Beyond Data Quality: Data Reliability

In other articles on this blog, we have discussed the importance of data quality. We have always approached this topic from the perspective of technologies that allow us to have control over data before it is processed by machine learning systems for subsequent decision-making. This control can be exercised at two levels:
1) Monitoring in real time with possible alerts when a significant decrease in any quality metric is detected. An example is when empty data or data with a cadence different from what is expected arrives.
2) Applying remediation mechanisms to try to keep the quality metrics above the established thresholds.
Today, we want to explore the concept of data reliability. This term is closely related to the concept of data quality. However, it adds an extra layer regarding the degree of confidence we can place in
What is Data Reliability
Unlike data quality, which refers to the validity of the data at a given moment, data reliability provides us with a measure of that validity, but in relation to a specific time window. In other words, it incorporates the time dimension into the set of indicators we typically use to calculate data quality: integrity, freshness, consistency, etc
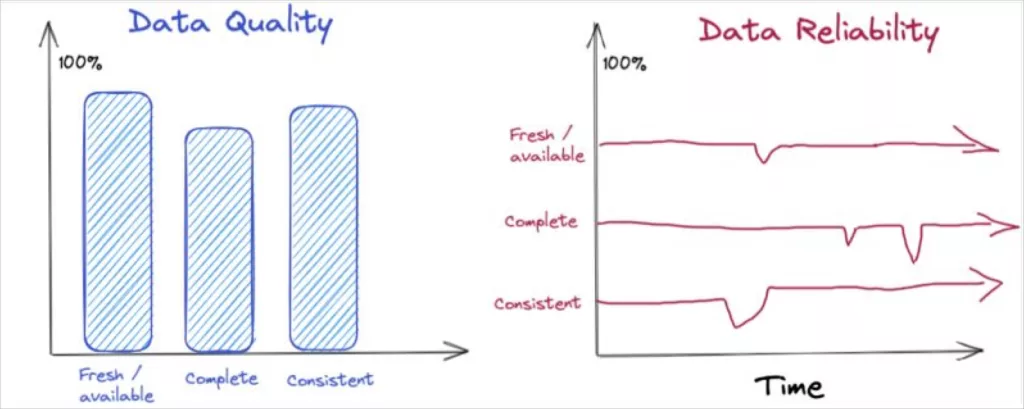
Data quality vs data reliability (by Shane Murray)
How to evaluate Data Reliability
An objective way to evaluate the reliability of a data flow could simply be to estimate the percentage of time during which the data is unusable because it does not meet the minimum necessary guarantees for its use. For example, retraining an AI model or making inferences with an already trained model. Considering that we have a system for detecting and managing quality incidents, this estimate, referring to a time period, would be calculated as:
number_of_incidents × [average_detection_time + average_remediation_time]
Based on this estimate, we can design global or specific evolution metrics for the different aspects of quality.
While data quality evaluation mechanisms can detect and alert about a specific quality issue, measuring data reliability requires continuously monitoring quality parameters over time. These reflect the service levels (SLAs) provided by our systems
Thinking in terms of reliability provides, on one hand, a measure of the impact caused by exogenous or endogenous issues in our data pipeline, for example, during capture or transformation processes. On the other hand, it also assesses how efficient we are in managing and remediating these issues.
Reliability vs Unavailability
Data reliability is inversely proportional to downtime. Therefore, maximizing reliability requires keeping downtime as low as possible. To achieve this, it is useful to adopt both reactive measures (reducing detection and remediation times) and proactive measures (investing more resources where the impact is greatest).
The reactive part necessarily relies on the most advanced and robust technology we can afford to act with the greatest speed when a data quality incident occurs.
Complementarily, the proactive part is related to prior work in risk analysis and economic impact assessment. It is necessary to identify the points at the business domain level where data is most critical (typically, where its use or consumption is highest). Additionally, the investment in monitoring technology will be based on the risk or impact avoided. In other words, prioritizing based on importance and focusing on what matters most.
Aplication to the Fintech sector
An example of applying data reliability technologies can be found in the project “Advanced Integration Technologies and Data Management for Fintech Platforms,” carried out by Gradiant in collaboration with the company Toqio. In this context, it is essential to have control mechanisms over customer data to ensure compliance with the established SLAs..
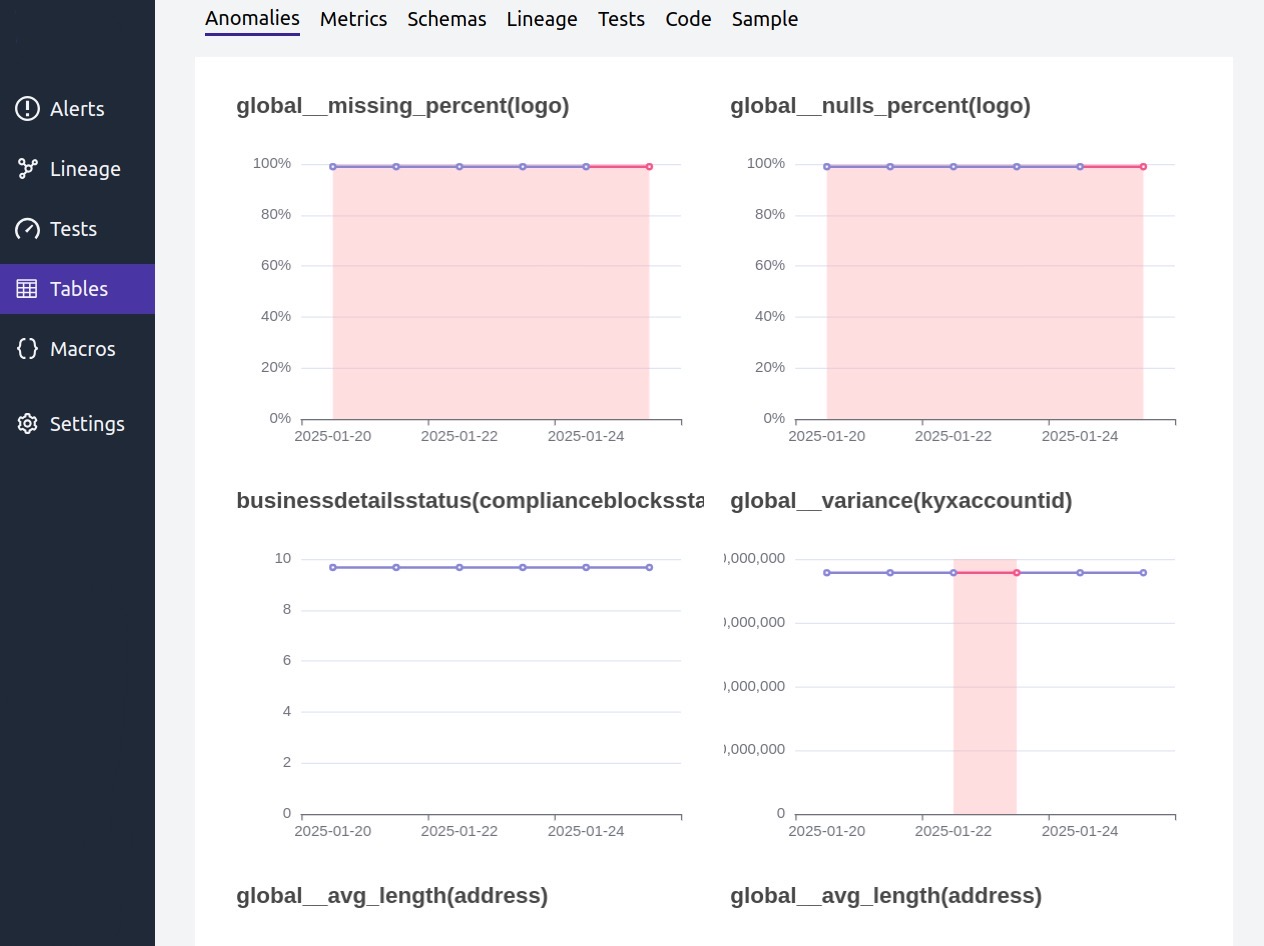
To carry out these tasks, data quality tools have been used, enabling detailed monitoring of data quality during the onboarding process of companies. These tools allow the implementation of various quality metrics, facilitating the temporal tracking of data and early intervention in the event of potential incidents.

Additionally, advanced techniques are applied for anomaly detection and continuous monitoring, which allows for the identification of unexpected deviations in the evolution of quality metrics. These anomalies are notified through an alert system that enables a quick response, preventing the propagation of unreliable data to other internal or external systems.


Project CPP2021-008971 funded by MICIU/AEI/10.13039/501100011033 and by the European Union NextGenerationEU/PRTR.R