Cloud Data Integration: A Modern Approach to Analytics in the Fintech EnvironmentImplementing a Data Lakehouse with CDC on AWS
Implementing a Data Lakehouse with CDC on AWS

In the era of digital transformation, data has become one of the most valuable assets for any organisation. The ability to collect, integrate and exploit information from diverse sources allows businesses to gain critical insights for decision-making, improve operational efficiency and maintain a competitive advantage in the marketplace. However, the true potential of this data is only realised when traditional silos are overcome and a coherent integration strategy is implemented. Modern organisations face the challenge of unifying structured and unstructured data, from transactional systems, cloud applications, IoT devices and external sources, all while maintaining information integrity, security and timeliness. Consolidating these heterogeneous streams into robust analytics platforms has evolved significantly with the emergence of architectures such as data lakehouses, which combine the flexibility of data lakes with the reliability and performance of traditional data warehouses.
But how do you implement a data lakehouse on AWS, integrating the Change Data Capture (CDC) process to efficiently capture and reflect changes in production systems? That is the question we will discuss in this article. Specifically, we will address the process of replication from NoSQL database systems such as MongoDB to a data lakehouse focused on enabling efficient data analytics. This implementation allows organisations to consolidate large volumes of heterogeneous data and prepare it for deep, real-time analysis.
This data integration architecture is particularly relevant to a number of business sectors, with a particular impact on the fintech arena. Financial technology companies operate in an environment where speed, accuracy and security of data are critical to their survival. A data lakehouse with CDC capabilities enables fintechs to process transactions in real time, while simultaneously analysing behavioural patterns to detect fraud, optimise credit risk assessment and personalise financial offers. The ability to maintain an immutable history of data changes not only facilitates compliance with strict financial regulations such as PSD2 or anti-money laundering regulations, but also enables the reconstruction of historical statements for audits or retrospective analysis.
Beyond the fintech sector, this architecture offers significant advantages for sectors such as retail, where it enables the analysis of shopping behaviour and real-time inventory optimisation; healthcare, facilitating the integration of medical records with medical device data for preventive medicine; manufacturing, where it enables predictive maintenance by integrating IoT data with production systems; and telecommunications, enabling the analysis of service quality and usage patterns to improve customer experience. In all these cases, the ability to synchronise operational data with analytics environments without creating additional burden on production systems represents a substantial competitive advantage.
Data Lakehouse Architecture: Converging Flexibility and Performance
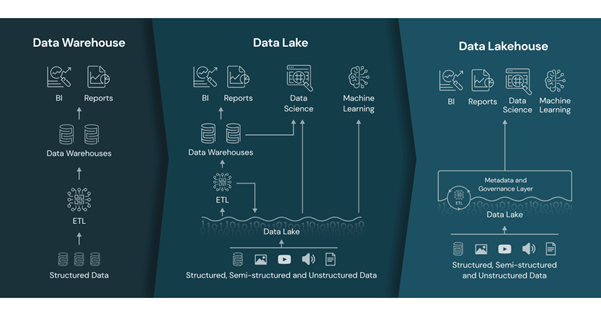
To properly understand a data lakehouse architecture, it is essential to first understand its foundational component: the data lake. A data lake is a centralized repository designed to store massive volumes of data in its original format—structured, semi-structured, or unstructured. In cloud environments like AWS, a data lake is typically implemented using storage services such as Amazon S3, which offers high durability, availability, and virtually unlimited scalability at a low cost.
Source: https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
However, traditional data lakes, while highly flexible in storage, present significant limitations when supporting complex analytical workloads. Their main challenges include the lack of transactionality, data governance issues, suboptimal performance for complex queries, and difficulties maintaining data quality and consistency.
This is where the data lakehouse concept comes into play. A data lakehouse is built by adding an additional technology layer on top of a data lake to provide capabilities traditionally associated with data warehouses: optimized query performance, transactional guarantees, and structured schemas. To implement this enhancement layer, it is necessary to select a table format that supports these advanced features, with Apache Iceberg being one of the most widely adopted in the industry.
Apache Iceberg functions as an abstraction layer over the physical files stored in the data lake, providing the functionality to turn it into a true data lakehouse. By implementing Apache Iceberg over a data lake based on S3 or other cloud storage systems, organizations can transform their basic storage infrastructure into a full analytical platform with:
- Support for updates and deletes: enables modification of specific records without needing to rewrite entire datasets, facilitating maintenance operations and regulatory compliance.
- ACID transactions: ensure consistency of operations even in distributed environments, preventing partial reads or inconsistent states during updates.
- Schema evolution: allows modifying the table structure without breaking existing queries, adapting to changing business requirements without disrupting analytical operations.
- Optimized queries: thanks to its hierarchical metadata structure, which avoids full data scans and significantly reduces response times and computational costs.
This layered approach (data lake + Apache Iceberg) provides all the benefits of a data lakehouse:
- Horizontal scalability: inherited from the underlying data lake infrastructure, allowing virtually unlimited growth. Since the data lakehouse is a storage layer decoupled from the processes needed to transform data, both can be scaled independently.
- Flexibility: storing data in its native format (JSON, CSV, Parquet, Avro, etc.) significantly reduces ingestion and initial processing time, allowing organizations to begin extracting value from their data more quickly. These native-format data can later be transformed into Apache Iceberg format within the data lakehouse.
- Near real-time data analysis: Traditional architectures forced a choice between optimization for writes (OLTP systems) or reads (OLAP systems), but not both. Data lakehouses, especially when implemented with technologies like Apache Iceberg and CDC processes, break this dichotomy.
- Optimized costs: maintaining the storage-compute separation inherent to cloud-native architectures, which allows scaling the data and processing layers according to the system’s workload. The data lake also implies lower storage costs (e.g., Amazon S3) compared to an equivalent data warehouse (e.g., Amazon Redshift).
Medallion Structure for Data Lakehouse Data Flow
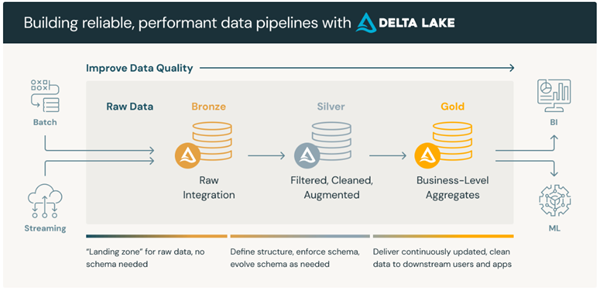
Before diving into the practical case, it’s important to understand how data flow is organized in a modern lakehouse architecture. A widely adopted approach is the medallion architecture, which structures data into three main layers commonly named bronze, silver, and gold (also referred to in some contexts as raw, refined, and curated, or other similar terms; the key is the progressive enhancement in data quality and value).
- The bronze/raw layer stores data as it arrives from sources, without transformation. It serves as a landing and historical backup zone.
- The silver/refined layer contains data that has been validated, cleansed, and transformed. This is where business rules are applied, and data is normalized to facilitate analysis and reuse.
- The gold/curated layer holds data already enriched and structured at the business level, ready for consumption by analytical tools, dashboards, machine learning models, or other strategic use cases.
Source: https://www.databricks.com/glossary/medallion-architecture
This tiered model allows progressive improvement of data quality and enables different analytical use cases in a flexible way, from basic exploration to predictive analysis.
Practical Case: CDC from MongoDB to Data Lakehouse on AWS
The following practical case represents a direct application of the layered approach of the medallion architecture. The initial raw ingestion corresponds to the bronze layer, storing data as it arrives from MongoDB via CDC. The silver layer is represented by data processed and cleansed using AWS Glue, transformed and stored in Iceberg format. Finally, the gold layer can be built from further refinements, applying aggregations and additional business rules using SQL in tools such as Amazon Athena, Redshift, or other compatible engines.
This approach has been put into practice within the “Advanced Integration Technologies and Data Management for Fintech Platforms” project, developed by Gradiant in collaboration with the company Toqio. Through this initiative, a modern data lakehouse architecture has been developed starting from an operational database such as MongoDB, aimed at facilitating near real-time data integration and analytics for strategic decision-making.
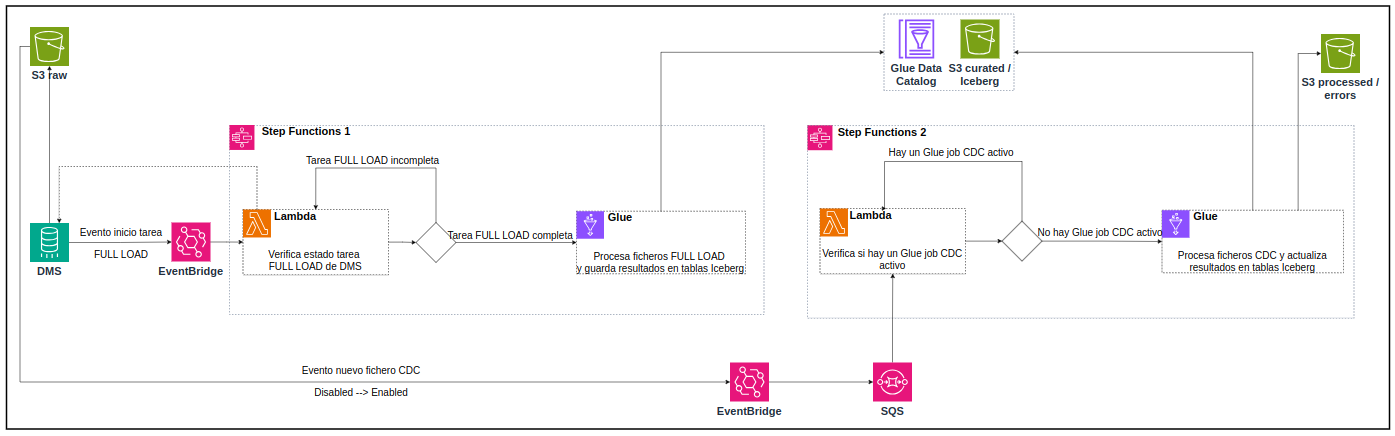
Figure: Architecture diagram of the implemented solution
Step 1. Change Capture with AWS DMS
AWS Database Migration Service (DMS) allows real-time replication of MongoDB data to Amazon S3 by capturing change events (CDC). Insert, update, or delete events are automatically stored in files (CSV or Parquet), reflecting the change history without manual intervention.
Step 2. Storage in Amazon S3
The captured data is stored in a first layer of raw data or raw zone (bronze layer). This first level of the data lakehouse retains the data as it arrives from the source system, serving as a backup and starting point for further transformation.
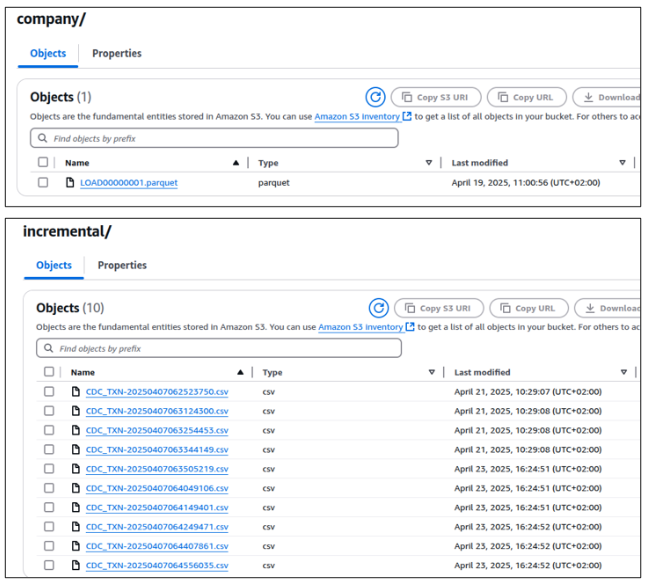
Figure: example of initial and incremental load files in the raw data bucket in S3 deep
Step 3. Orchestrating the Incremental Process
From the raw layer in S3, an incremental workflow is triggered using various AWS services:
- Amazon EventBridge: detects key events such as the start of DMS load tasks or the arrival of new CDC files in the S3 bucket, and automatically triggers corresponding workflows.
- Amazon SQS: provides a message queue to ensure that events are managed in an orderly fashion and that no executions are lost or overlapped.
- AWS Lambda: serverless functions triggered by EventBridge events and SQS messages perform initial validations and launch Glue processing jobs.
- AWS Step Functions: coordinates and orchestrates the entire processing flow, including validations, error handling, and dependent tasks.
Step 4. Analytical Layer
Once the data has been transformed and written in Iceberg format, it becomes part of the silver or refined layer. In this layer, data is already structured and ready for efficient querying, enabling data teams to execute SQL queries quickly and reliably, without needing to replicate data into an additional relational database.
The tables can be queried from Amazon Athena, Redshift, Spark, Presto, or other Iceberg-compatible engines, allowing seamless integration with dashboards, analytical notebooks, or machine learning models.
From here, additional transformations, business rules, and aggregate calculations can be applied, giving rise to the gold or curated layer, which is designed to deliver direct analytical value and is ready for business consumption.
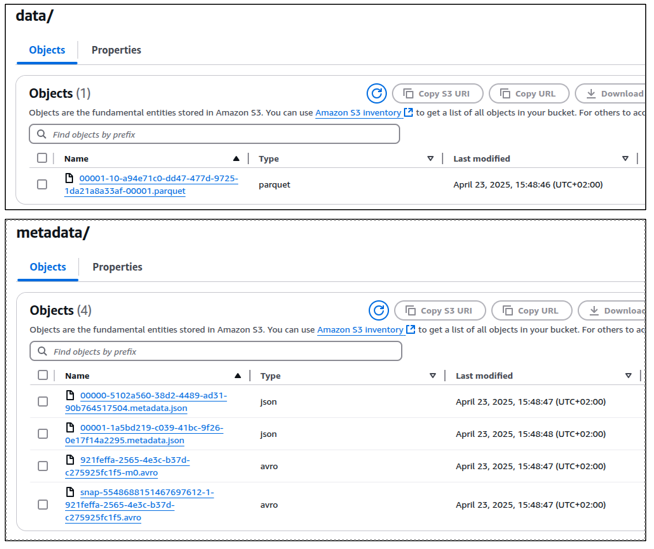
Figure: structure of the data objects and metadata generated in S3 after the transformation process and saved in Iceberg format
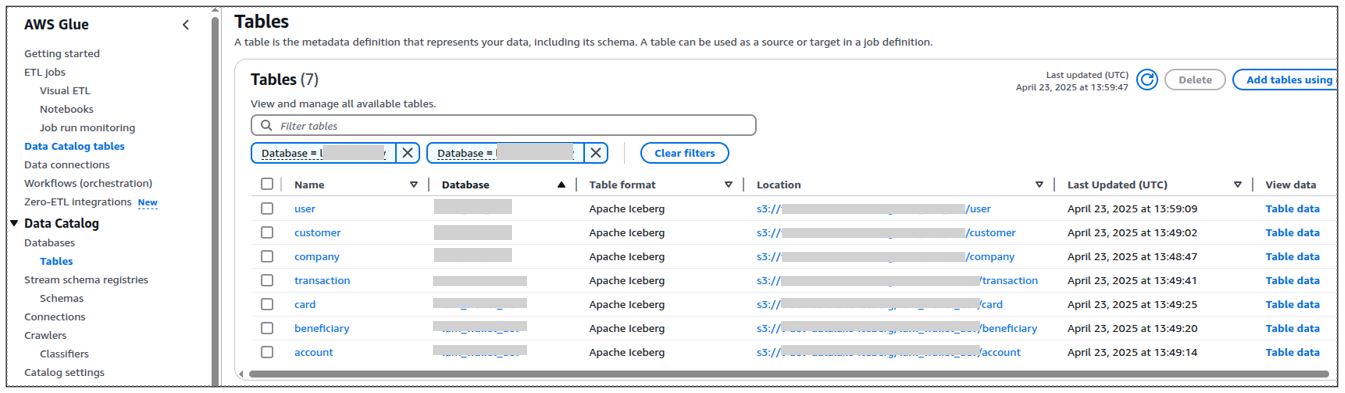
Figure: Iceberg tables are registered in the AWS Glue data catalogue, from where they can be accessed via Athena.
Conclusion
A CDC-based data lakehouse from operational sources enables organizations to build a modern, scalable, and future-proof analytical infrastructure. The presented architecture leverages open-source technologies such as Apache Iceberg and Apache Spark, along with a suite of managed AWS services including DMS, S3, EventBridge, SQS, Lambda, Glue, and Step Functions.
This approach eliminates the need for massive periodic ETLs, improves the freshness of analytical data, and reduces operational complexity. By combining open-source tools with scalable cloud services, it delivers a robust and cost-effective solution that is ready to evolve and incorporate new data sources.
All of this enables more agile analytics based on up-to-date data, helping improve decision-making across different areas of the business.
Authors: Diego Reiriz Cores, technical manager of AI & Data Ops; Sergio González Rodríguez, AI & Data Ops engineer from Intelligent Systems Department

Proyecto CPP2021-008971 financiado por MICIU/AEI/10.13039/501100011033 y por la Unión Europea NextGenerationEU/ PRTR