Más allá de Data Quality: Data Reliability

En otros artículos de este blog, hemos tratado la importancia de la calidad de datos (data quality). Siempre hemos abordado este tema desde la perspectiva de tecnologías que permiten tener un control sobre los datos antes de ser procesados por sistemas de aprendizaje automático para la posterior toma de decisiones. Este control podemos ejercerlo a dos niveles:
1) Monitorizando en tiempo real y con posible alertado cuando se detecta una disminución significativa en alguna métrica de calidad. Un ejemplo, es cuando llegan datos vacíos o con una cadencia diferente a lo esperado.
2) Aplicando mecanismos de remediación para tratar de mantener las métricas de calidad por encima de los umbrales establecidos.
Hoy queremos explorar el concepto de fiabilidad de datos (data reliability). Este término está íntimamente relacionado con el concepto de calidad de datos. Sin embargo, supone una vuelta de tuerca adicional respecto al grado de confianza que podemos depositar en las métricas de calidad, ya que extiende la noción de observabilidad sobre los datos que atraviesan nuestros sistemas.
Qué es Data Reliability
A diferencia de data quality, que se refiere a la validez de los datos en un momento dado, data reliability nos ofrece una medida de esa validez, pero referida a una ventana temporal determinada. Es decir, incorpora la dimensión tiempo al conjunto de indicadores con los que calculamos habitualmente la calidad del dato: integridad, frescura, consistencia, …
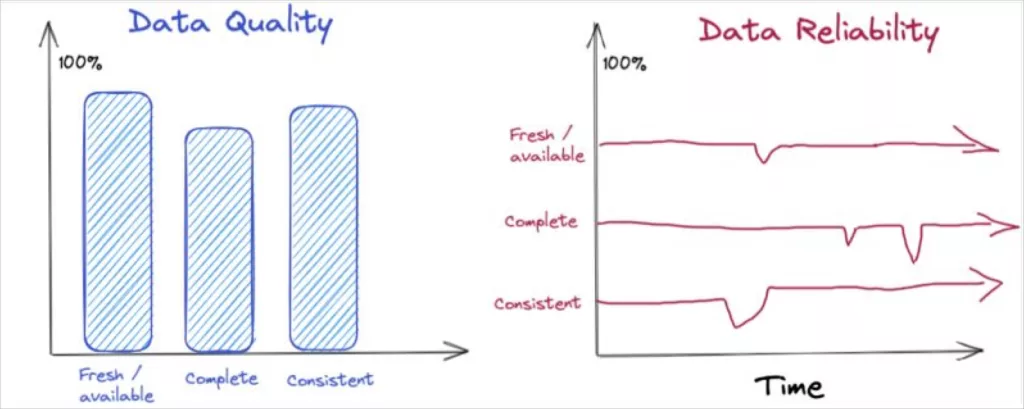
Data quality vs data reliability (cortesía de Shane Murray)
Cómo se evalúa Data Reliability
Una manera objetiva de evaluar la fiabilidad de un flujo de datos puede consistir simplemente en estimar el porcentaje de tiempo en que los datos no son usables porque no reúnen las garantías mínimas necesarias para su explotación. Por ejemplo, reentrenar un modelo de IA o hacer inferencia sobre un modelo ya entrenado. Al considerar que disponemos de un sistema de detección y gestión de incidentes de calidad, esta estimación, referida a un período de tiempo, se calcularía como:
número_de_incidentes × [tiempo_medio_de_detección + tiempo_medio_de_remediación]
A partir de esta estimación, podemos diseñar métricas de evolución globales o particularizadas para los distintos aspectos de calidad.
Mientras, los mecanismos de evaluación de la calidad del dato pueden detectar y alertar de un problema puntual de calidad, medir la fiabilidad de los datos exige monitorizar los parámetros de calidad a lo largo del tiempo, de forma continua. Estos son un reflejo de los niveles de servicio (SLAs) que proporcionan nuestros sistemas.
Pensar en términos de fiabilidad brinda, por una parte, una medida del impacto causado por problemas exógenos o endógenos en nuestro pipeline de datos, por ejemplo, durante los procesos de captura o transformación. Por otro lado, también evalúa lo eficientes que somos en la gestión y remediación de estos problemas.
Fiabilidad vs indisponibilidad
La fiabilidad de los datos es inversamente proporcional al tiempo de indisponibilidad (downtime). Por tanto, maximizar la fiabilidad requiere mantener el tiempo de indisponibilidad lo más bajo posible. Para esto, es conveniente adoptar medidas tanto reactivas (reducir los tiempos de detección y de remediación) como proactivas (invertir más recursos donde el impacto sea mayor).
La parte reactiva se sustenta necesariamente en la tecnología más avanzada y robusta que nos podamos permitir para actuar con la mayor celeridad cuando se presenta un incidente de calidad de datos.
De forma complementaria, la parte proactiva la relacionamos con un trabajo previo a nivel de análisis de riesgos e impacto económico. Se deberá identificar los puntos a nivel de dominio de negocio en que los datos son más críticos (normalmente, donde su uso o consumo es mayor). Además, la inversión en tecnología de monitorización se basará en el riesgo evitado o en el impacto evitado. Es decir, priorizar según importancia y enfocarnos en lo que importa más.
Aplicación al sector fintech
Un ejemplo de aplicación de tecnologías de data reliability lo encontramos en el proyecto “Advanced Integration Technologies and Data Management for Fintech Platforms”, que realiza Gradiant en colaboración con la compañía Toqio. En este contexto, es esencial disponer de mecanismos de control sobre los datos de los clientes para asegurar el cumplimiento de los SLAs establecidos.
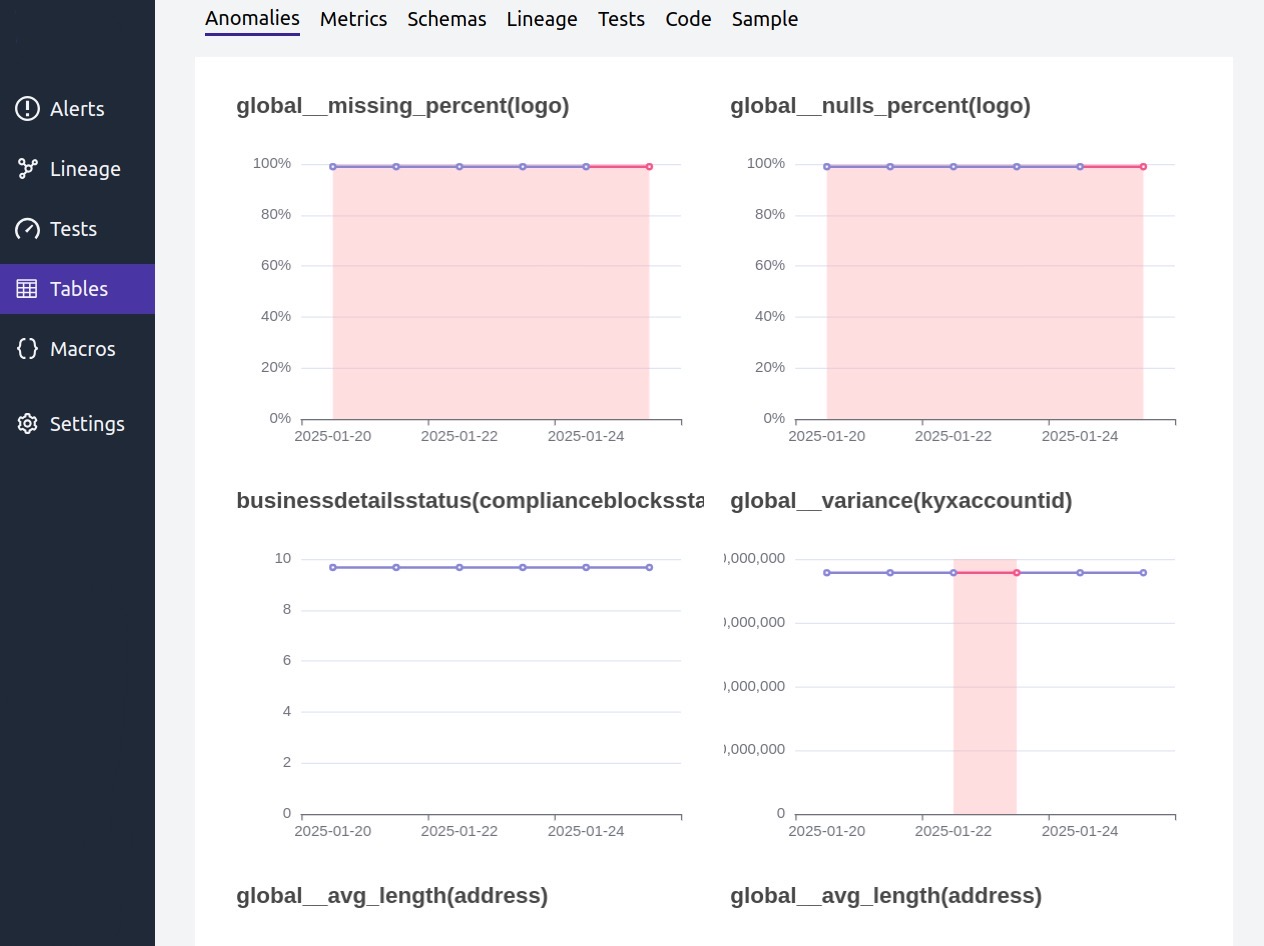
Para la realización de estas tareas se han usado herramientas de data quality que han permitido realizar un seguimiento detallado de la calidad de los datos durante el proceso de onboarding de las compañías. Estas herramientas habilitan la implementación de diferentes métricas de calidad, facilitando el seguimiento temporal de los datos y la intervención temprana ante posibles incidencias.

De forma adicional, se aplican técnicas avanzadas para la detección de anomalías y monitoreo continuo, lo que permite identificar desviaciones inesperadas en la evolución de las métricas de calidad. Estas anomalías se notifican mediante un sistema de alertas que facilita una respuesta rápida, evitando la propagación de datos no fiables a otros sistemas de la compañía o externos a ella.


Proyecto CPP2021-008971 financiado por MICIU/AEI/10.13039/501100011033 y por la Unión Europea NextGenerationEU/ PRTR